<see part one for the whole story>
While mulling my options for the next steps on this project, I got some feedback
i think the backgrounds will be your biggest issue…that followed by the healthbars / items equipped…trying to normalise for that will probably help a lot ?
Tom Cronin – via Linkedin
Which completely changed my view on the problem.
Firstly, I’d thought the background were *helpful* – the high contrast with the characters, and then the different backgrounds that players use to provide variety. A problem I’d not considered is how much extra complexity they add into the image, and how much more training might be needed to overcome that.
Secondly, I’d been thinking my task was to collect and annotate as many images as possible.
I’ve been doing it wrong.
The (new) approach
I can easily ‘cut’ the characters out from their backgrounds

But then the problem is that I don’t want the computer thinking a solid white rectangle is anything meaningful to the character. So what if I take the cut out, and make some new backgrounds to put it on. Then I’m killing two birds with one stone:
- I can create any background I like; colours, shapes, pigeons.. and:
- I can create LOTs of them
So rather than screenshotting and annotating, my new approach is:
- Cut out a lot of character images (this is tedious, but once it’s done, it’s done forever.. or until the next patch)
- Create some random backgrounds
- Stick the characters over the new backgrounds
- Auto-generate the boundaries I had to draw manually last time
Step 0
There’s always a step 0.
Up to this point, I’ve been hacking about, every step is manual, most of them are ‘found’ by clicking up and down through the terminal window.
I’ve now written a single script which automates:
- Clear output folders
- Create images (and the annotation file)
- Create test/train split
- Create TFRecord files
(at some point I’ll automate the run too, but this at least gives me a start)
Step 1 – Cut out a lot of images
This isn’t very interesting, but I noticed through the process that the characters move about a bit. Just small animation loops for most, but some even flip sides. On that basis, I’ve used a naming convention for the files which allows me to have multiple copies
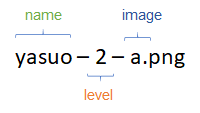
Each character has 3 levels, which are gained as you get more of them (3 of the same magically transforms into level 2, and 3 level 2s become a level 3). Power increases quite significantly with level.

I keep the first two sections as the class I’m trying to predict, but ignore the suffix.
Step 2 – Create some random backgrounds
Thinking about the backgrounds, I initially went with 2 options – a blurry ‘noise’ of colour, and a single flat colour. The overall intent is that the computer loses the overall background as it learns, and just focuses on the character.

I noticed in early testing that computer was labelling some odd things like parts of my desktop background, while failing on actual screenshots from the game. I decided to add in a handful of random backgrounds from the game (with any characters removed) to give some realism to the sample

Step 3 – Stick the characters over the new backgrounds
I then load a random character image (so random character, level and pose) from my input folder, and add it to the image. I’ve also added a chance for the image to be resized up or down a little before it’s added – this is to cover the slight perspective the game adds, where characters in the background are smaller.
I repeat the loop 20 times for each image, and save it down with the xml


Step 4 – Auto-generate the boundaries I had to draw manually last time
I was very pleased when this worked.
The most tedious task of the original attempt is now gloriously automated. Each character image reports it’s location and size, and is added in to the correct xml format.
I can now create hundreds, or thousands of files to use as inputs!
So, what does this do to the graph?!
(I should note, with this change I’ve also tweaked some parameter files. I’m not entirely sure of the sensitivity, but each run now uses multiple images. This might only have the effect of doubling the time per step, and halving the number of steps needed. Idk)
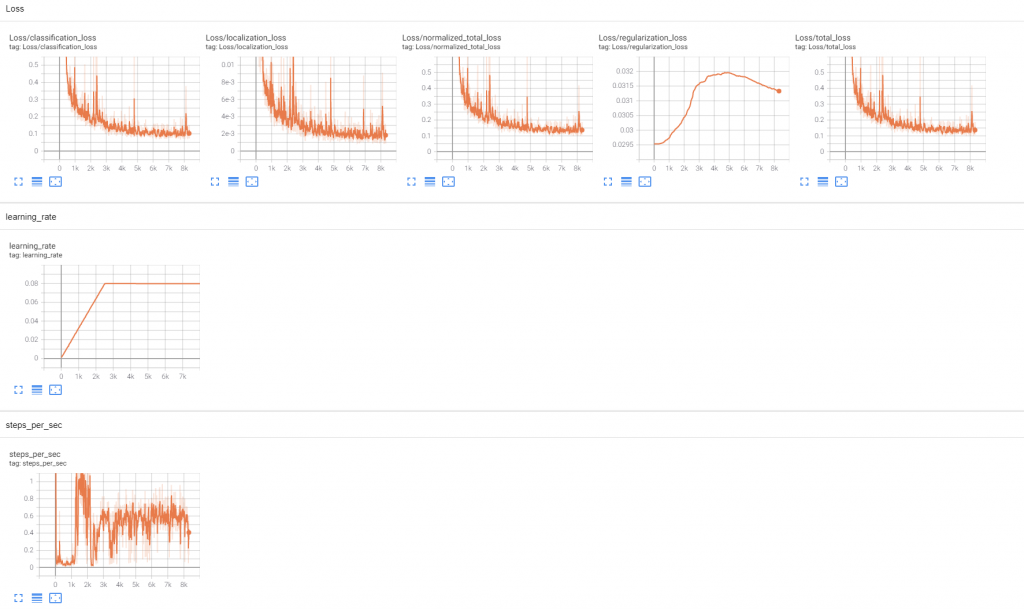
Well, a few things look different:
My loss (which I’m assuming is the equivalent of 1/accuracy) behaves much more at the start, and quickly follows a steady curve down.
The time/step is *horrendous* for the first 1k steps. The run above was over 6 hours.
tl;dr – did it work?!
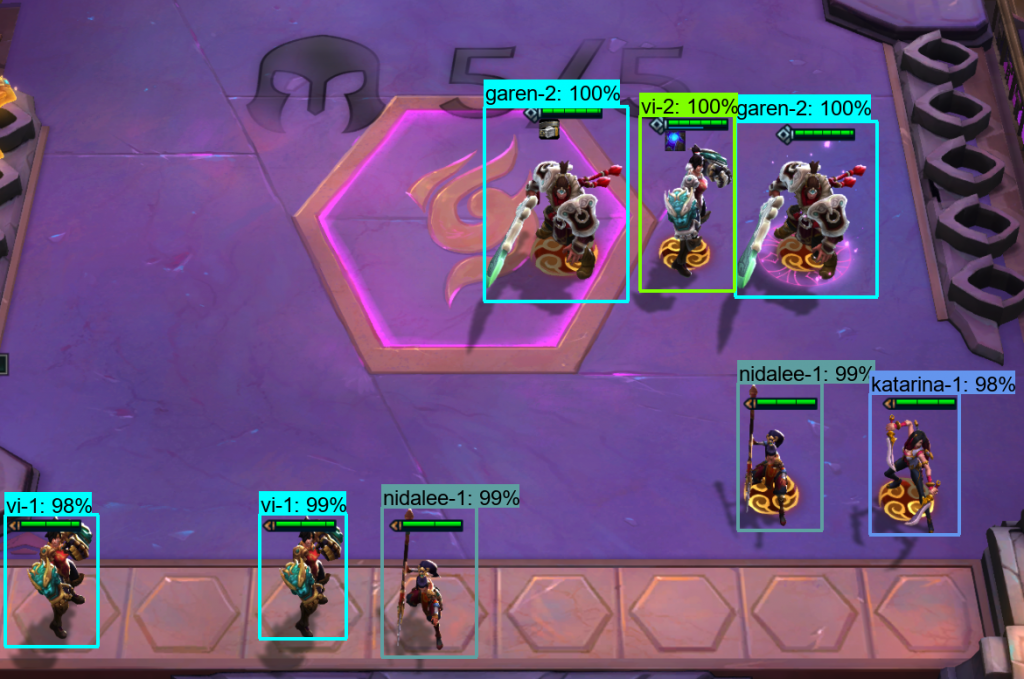
Just a bit.
This isn’t just better, it’s remarkable. Every character is guessed, and the strength of the prediction is almost 100% each time. It’s spotted the difference between the Level 1 & 2 Vi, and even handled the inclusion of an ‘item’ (the blue sparkly thing below her green health-bar)

Appendix
The early run (pre the inclusion of backgrounds) did better than before, but still lacked the high detection numbers of the most recent model

It’s especially confused when the background gets more complex, of there’s overlap between the characters.
I’ve also started looking at running this on screen capture, rather than just flat images. I think the hackiness of the code is probably hampering performance, but I’m also going to look at whether some other models might be more performant – e.g. those designed for mobile.
Pingback: Using Object Detection to get an edge in TFT [pt1] | Alex's Blog