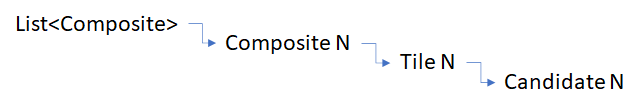Half hangman, half mastermind, Wordle is a fun new obsession for half of the internet. Fun as it is to try and remember 5 letter words, what if I got the computer to solve it?
The Problem
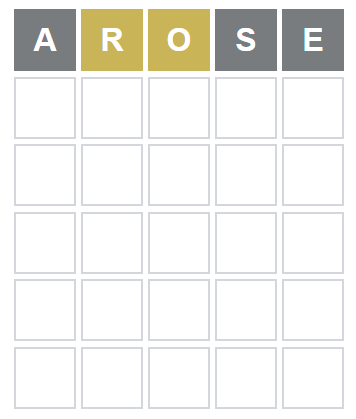
You get 6 guesses to find the word of the day. Each guess is assessed and you find out which letters you guessed correctly (i.e. appear in the word) and if any of those are in the right position in the word. It looks like this:
Grey means the letter isn’t in the word Yellow is in the word, but not in the right place Green is correct
In this example, the first guess is pure chance.
There is one word each day.
The Solution
My first solution will run through 3 steps: 1. Read in a defined wordlist 2. Read in any previous guesses with the results 3. Strip out words from the wordlist based on the guesses 4. Generate a new guess
I don’t think there’s any way to do this without starting with a list of possible words. without this we’re just guessing symbols, and part of the nature of the puzzle is the players knowledge of english words.
Each guess generates information about the true word.
Grey – the letter is not in the word at all Yellow – the letter is in the word, but not where the guess has put it Green – the letter is in the word and is in the right place
There are some subtleties to the yellow and green options – in both cases there is the potential for a letter to appear twice, it’s easy as a novice player to incorrectly assume green means job-done for that letter. Equally yellow is as much about narrowing down valid letters as it is about restricting the possibilities for the square.
3. Strip out words based on the information from the guesses
I’m going to loop through all the remaining words on the wordlist and prune them in one of 3 ways:
Remove any word containing any number of grey letters
For yellow letters, remove words with that character in that position, and also words where that character isn’t in at least one other position
For green letters, remove any words without that letter in that position
By gradually sifting through the words, I end up with a smaller list of possible words which fulfil the ‘rules’ as they evolve.
4. Generate a new guess
I want to use some tactics with each guess, it’s not helpful to have the algorithm only change a single letter at a time, or I’ll run out of guesses. The game also requires each guess to be a real word.
‘Splittiness’
I’m going to use an approach similar to a decision tree for v1. I’ll start by working out how many words each letter appears in, and then what fraction of the total words that represents:
S
46%
Y
15%
E
46%
M
14%
A
38%
H
14%
R
31%
B
12%
O
29%
G
11%
I
27%
K
10%
T
25%
F
9%
L
25%
W
9%
N
21%
V
5%
D
19%
X
2%
U
19%
Z
2%
C
16%
J
2%
P
16%
Q
1%
Here S & E are the ‘winners’ – they’re each present in almost half of the words in the list. This is useful because guessing a first word with them will allow me to split the wordlist most evenly and remove/include a large number of possible words, reducing my search space considerably.
For later versions, I want to look at the overlap between them, e.g. if most words containing S also contain E, it might be that the first guess is better to skip E, and try the next letter down.
The best starting word, the word which will give me the best split between words I should include and remove contains S,E,A,R,O
Anagramming
SEARO is, unfortunately not a word, so the next step is to try the different permutations of the letters until I get something which is (more-so, something which is a word on my wordlist – so it’s still a viable guess).
First guess is easy enough, a simple iteration through the permutations of the letters comes up with – AROSE. I can use all the letters in a viable word, but I need a strategy to ensure I don’t get stuck further down the line. Even one letter down, EAROI doesn’t yield a valid 5 letter English word.
My solution is to add another level to my anagram solver, My preference is to have the 5 most splitty letters, but I’d take 1,2,3,4,6 if they didn’t work, and 1,2,3,4,7 after that. I now have a way to ensure that I’ll be able to sweep the full range of available letters, hoping I’m stepping ever nearer the right answer.
Rinse and repeat
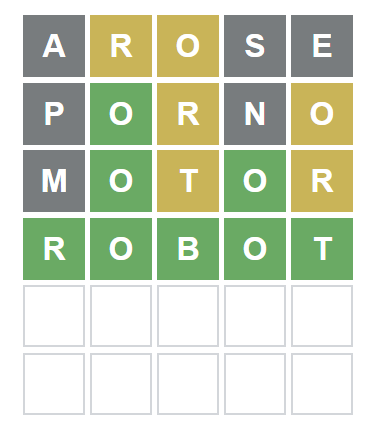
Putting AROSE into the puzzle gives me
And then I repeat the process, putting in the results and asking for the next best word to try, until the board looks like this:
This is Wordle 215, from 20/1/22, and with only 4 guesses needed, 1 better than my personal attempt!
There’s a tangible sense of the algorithm building on what it learns each round.. but also a tedious inevitability that it will reach a valid answer at the end.
I suppose part of the challenge of wordle is the need for a human to remember all the possible words and to make efficient choices. This bit of coding has helped me understand the puzzle at a lower level.
Update – 21/1/22
Wordle 216 6/6
⬜?⬜⬜⬜ ⬜?⬜?⬜ ???⬜⬜ ⬜??⬜? ⬜???? ?????
Today’s word was solved, but I learned 2 things: 1. My algorithm will happily guess double letters which it has no evidence exist in the word – I think this is sub-optimal 2. If you guess the same letter twice, and it’s in the word once, you’ll get two yellow blocks if they’re in the wrong places, but a green and a grey (not yellow) if one of them is correct
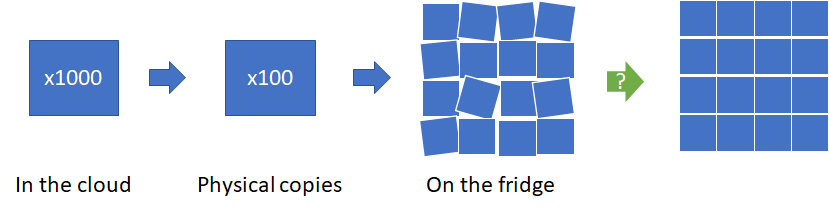
In Part 1 I put together a short python script to automate the stitching together of 16 pictures into a single composite. Now I want to take some of the effort out of selecting the 16 pictures, in order to speed up the process
Each month my wife and I choose 16 of the best pictures involving our son from the hundreds we’ve taken. These end up on our fridge in a 4×4 grid. Although we take a picture of the pictures on the fridge, it always looks a bit screwed up and it’s nice to have a good version stitched together on the computer.
How can I minimise the effort needed to recreate a physical collage from a photo?
The problem
The problem looks a bit like this:
As part of the selection, we have up to 100 printed out into actual photos, so we can isolate the image files for those, but the refinement to the final 16 is done by hand.
Read in the individual images, and a picture of the ‘raw’ composite from the fridge
Break the raw composite down into 16 tiles
Check each of the individual images against the tiles
Present the user with the original tile and an ordered list of the ‘candidate’ images which are the best match
Loop for all 16, then stitch the final image together
1. Read in the images
I’m going to use a combination of OpenCV and Pillow for my image processing, the first step will be in OpenCV so I’ll read the files in like that.
I’ve created some objects to hold the data around each image – my foray into C# a few years ago got me thinking in Objects, and although I’m not sure it’s Pythonic (dahling), it helps me order my thoughts, and write more debuggable code
class Composite:
imageName: str
rawImage: Image.Image
pilOutputImage: Image.Image
outputImageArr: list
tiles: list
candidates: list
readyToProcess: bool
done: bool
imageXSize: int
imageYSize: int
date: datetime
def __init__(self, _imageName, _rawImage, _imageX _imageYSize):
self.imageName=_imageName
self.rawImage=_rawImage
self.tiles=[]
self.candidates=[]
self.outputImageArr=[]
self.readyToProcess=False
self.done=False
self.imageX=_imageX
self.imageYSize=_imageYSize
self.pilOutputImage = Image.new('RGB', (_imageX4, _imageYSize*4),(255,255,255))
self.date=datetime.datetime.strptime(_imageName.split(".")[0],'%b%y')
def incompleteTiles(self):
return [t for t in self.tiles if t.done==False]
def pilImage(self):
return Image.fromarray(self.rawImage[:,:,::-1].astype('uint8'))
def buildImg(self):
for tile in self.outputImageArr:
Image.Image.paste(self.pilOutputImage, tile.pilImage(), (self.imageXtile.xPos, self.imageYSize*tile.yPos))
def addCompleteTile(self, tile):
self.outputImageArr.append(tile)
Image.Image.paste(self.pilOutputImage, tile.pilImage(), (self.imageXtile.xPos, self.imageYSize*tile.yPos))
This is an example of the ‘Composite’ object – there will be one of these for each of my Raw Composite files (the fridge images). This holds the rest of the information relating to the Tiles (the 16 sub images) and the Candidate images. It also has the logic to build the final output image.
class Tile:
xPos: int
yPos: int
rawImage: Image.Image
candidates: list
done: bool
def __init__(self, _x, _y, _rawImage):
self.xPos=_x
self.yPos=_y
self.rawImage=_rawImage
self.candidates=[]
self.done=False
def pilImage(self):
return Image.fromarray(self.rawImage[:,:,::-1].astype('uint8'))
This is a Tile. It knows what it looks like in a raw form, it’s position on the 4×4 grid, and the candidate images which could be it
Finally this is an image, I use it to keep some of the important info relating to the image in a single place. It’s got the concept of ‘Error’ in there, which will come from the matching code – the lowest error is our best candidate
This is my rough data structure, now I need to populate it
This function loads raw images (in OpenCV format – a numpy array) and creates an appropriate object to hold them. Theres some extra data (like date, and image size) which is useful later on.
2. Breaking out the tiles
This is a bit of a fudge. Because the pictures taken from the fridge are imperfect, it’s difficult to cut out the exact image, but the hope is that the matching process will work ok with a rough target.
def detile(name, image, imageXSize, imageYSize):
outArr=[]
for x in range(0,4):
for y in range(0,4):
im=image[y*imageYSize:(y+1)*imageYSize,x*imageXSize:(x+1)*imageXSize]
outObj=Tile(x, y, im)
outArr.append(outObj)
return outArr
So I just loop through a 4×4 grid, cut each image and make a new tile out of it. Once that’s done, it gets added to the Tiles list in the Composite object
3. Checking for matches
Let’s assume I have 100 candidate images for my 16 tiles. That’s 1,600 checks which need to be done, and that’s going to take some time. This seemed like a good excuse to have a play with Threading in python
I’ve tried threading before in C#, and it felt messy. I’ve never really had proper training, so I just google my way through it, and I wasn’t ready to handle the idea that information would be processed outside of the main thread of my program. It was really useful (e.g. for not having the UI lock-up when heavy processing was happening), but I didn’t properly understand the way I was supposed to handle communication between the threads, or how to ‘safely’ access common sources of info.
This time, things are a bit simpler (and I’ve been thinking about it for a few more years).
I need my threads to work on the checking algorithm
def wrapper_func(tileQueue, rawImages):
print("thread")
while True:
try:
tile = tileQueue.get(False)
for image in rawImages:
result = cv2.matchTemplate(tile.rawImage, image.rawImage, cv2.TM_SQDIFF_NORMED )
mn,mx,mnLoc,mxLoc = cv2.minMaxLoc(result)
output=Img(image.imageName,image.rawImage, 0)
output.error=mn
tile.candidates.append(output)
tileQueue.task_done()
except queue.Empty:
pass
Here I have a queue of tiles, and my raw images. Each tile needs to be checked against all the images, but there’s no reason why they can’t be checked independently of each other. This ‘wrapper function’ – which still uses the function name from a StackOverflow answer I cribbed (this one, I think) – is run in 8 different threads, and checks each tile against all the raw images, appending a candidate to the tile each time.
I’m pretty sure this qualifies as thread-safe. The append operation just adds new stuff in, and I’m not reading from anywhere in the list.
def check_matches(composite, rawImages):
print("check_matches.. may take a while")
tileQueue=queue.Queue()
for tile in composite.tiles:
tileQueue.put(tile)
for _ in range(8):
threading.Thread(target=wrapper_func, args=(tileQueue, rawImages)).start()
tileQueue.join() #wait until the whole queue is processed
for tile in composite.tiles:
tile.candidates.sort(key=lambda x:x.error) #sort the candidates by error (the error of the match)
composite.readyToProcess=True
print(composite.imageName+" ready to process")
Stepping out a layer, this processes an entire composite. First splitting into a queue of tiles, then fire this into 8 threads. Once the queue is processed, sort the candidates, then set a ‘ready to process’ flag for the UI to respond to.
def loop_composites():
thread.join()
print("looping composites")
global readyState, rawComposites, rawImages
for composite in rawComposites:
print(composite.date)
compMinDT = composite.date-timedelta(days=30)
compMaxDT = composite.date+timedelta(days=30)
rawImagesFiltered=[i for i in rawImages if (i.exifDT>=compMinDT and i.exifDT<=compMaxDT) or i.exifDT==datetime.datetime(1900, 1, 1, 00, 00)]
matchThread = threading.Thread(target=check_matches, args=(composite, rawImagesFiltered))
matchThread.start()
matchThread.join()
This is the outer layer of the loop. I’ve added in some filtering logic which uses the exif data to say when the photo was taken. All fridge photos are from a 1 month period (aligned to the middle of the month), so I can use the composite date and check for a period either side. This should reduce the processing if I want to run many months at the same time.
4. The UI
I’ve decided that there’s no way this process will work without a human in the loop – the whole point is to have the correct image at the end!
I’m using Flask to serve a simple web front end which will present the user with the images, and allow them to choose the correct one
On the left you can see the original composite image – you can see that the overall images are a bit skewed, and there’s significant light distortion on the left hand of the image
In the middle is the 1st tile cut from the raw composite
Next is the first match candidate (it’s correct! yay!)
Then is a placeholder for the newly constructed image
5. Loop, complete, stitch and save
Clicking ‘correct’ adds the candidate to the output image array, and pastes the image into the right hand ‘progress’ image
And once all the tiles have a match, the image is saved
Success! Original ‘fridge’ picture on the left, and new composite on the right – blurred to protect the innocent
6. How did we do
The original reason for creating this program, other than the fun of making it, was to reduce the time it took to create the composites. Let’s consider two metrics:
How many images did I need to click through to get to the final composite
How many times did the program get the right image first time
Jun 21
Jul 21
Total Clicks
202
39
Right first time
11
10
With around 100 photos per month, I only needed to check 5-6 of them, and worst case I needed 40 clicks for each of the remaining photos. I think that’s pretty good.
AKA Where should my parents-in-law be looking for a house?
With grandchildren numbers rapidly increasing, my wife’s parents have decided to move closer to her and her sister. Houses are uniformly laid out, and roads aren’t always conveniently point-to-point, so this has lead to discussions about what area is suitable for the search
The problem
Given two anchor locations, and a maximum drive time to each, what is the correct region in which my parents-in-law should search for a house.
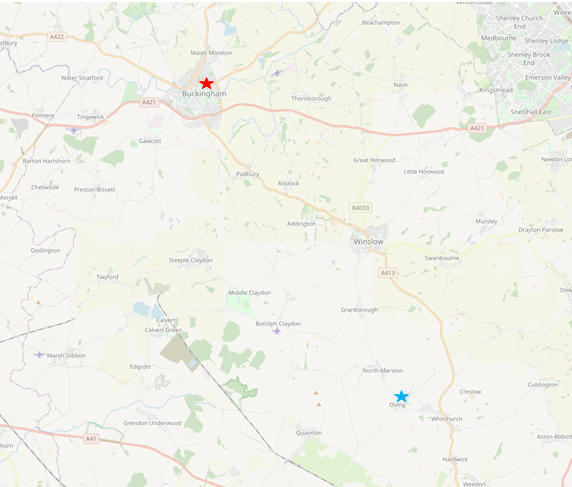
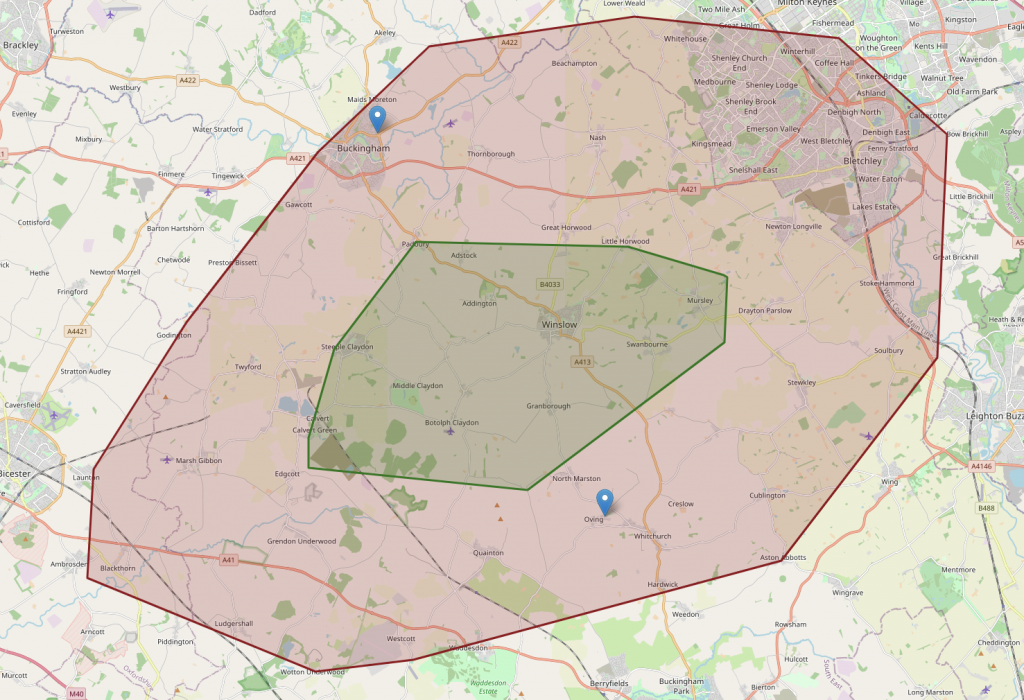
Without being too specific, the red and blue stars are our anchor locations
The solution
After the obligatory googling, I think I’ve found the bones of a solution:
OSMnx – This provides a way to pull data from OpenStreetMap (OSM), including the places, roads and map itself. There are some excellent examples in the git repo, and Geoff Boeing seems to be something of the god in this field
networkx / geopandas – Some useful functions for doing the maths
Folium – For displaying my output
My steps are:
Find 2 OSM nodes to represent my locations
Create a zone around each which represents the distance which can be travelled in a given time
Find the intersection between those two zones
Draw it on a map
1. Finding my points
From the brief time I’ve spent looking at it, OSM seems to work on two main data features, Nodes and Edges. A node is a location of interest on the map, and could be something like a house or shop, or might just be a bit of road. The edges are the (hopefully) legal moves between nodes, and come with some useful metadata like the speed limit on a particular road, and the distance.
For starters I’ll create variables with the rough locations we’re working from
#Setup some locations to work with, my two locations, and a roughly midpoint (might be useful later)
oving=(51.88550,-0.85919)
buckingham=(52.00271, -0.97210)
midPoint=(52.00,-.9)
Then use the OSMnx package to pull back map detail from that
I then use get_nearest_node to give me a known node close to both of my locations, finally ‘projecting’ the data, which as best I understand it, means I’m taking the 3d Lat/Long information, and flattening it to a 2d co-ordinate system from further analysis.
2./3. Create the travel zone around each / find the intersection
This is pulled from another piece of code in the OSMnx git examples, I think the idea is that the ego_graph is able to find all the nodes within a certain distance of the original – in this case the distance is time:
#Use the networkx 'ego_graph' function to gather all my points with a 25 minute drive time
ovingSubgraph = nx.ego_graph(G, oving_center_node, radius=25, distance='time')
buckinghamSubgraph = nx.ego_graph(G, buckingham_centre_node, radius=25, distance='time')
#To create the overlap, I found this snippet of code which just removes the nodes only in one side
jointSubgraph=ovingSubgraph.copy()
jointSubgraph.remove_nodes_from(n for n in ovingSubgraph if n not in buckinghamSubgraph)
Then we need to create some polygons which enclose all the nodes:
#For each location, get the points, and then use geopandas to create a polygon which completely encloses them
ovingPoints = [Point((data['lon'], data['lat'])) for node, data in ovingSubgraph.nodes(data=True)]
ovingPoly = gpd.GeoSeries(ovingPoints).unary_union.convex_hull
buckinghamPoints = [Point((data['lon'], data['lat'])) for node, data in buckinghamSubgraph.nodes(data=True)]
buckinghamPoly = gpd.GeoSeries(buckinghamPoints).unary_union.convex_hull
jointPoints = [Point((data['lon'], data['lat'])) for node, data in jointSubgraph.nodes(data=True)]
jointPoly = gpd.GeoSeries(jointPoints).unary_union.convex_hull
4. Draw it on a map
Then, finally plot the 3 regions, and 2 locations on a folium map
#Define some styles for my areas
style1 = {'fillColor': '#228B22', 'color': '#228B22'}
style2 = {'fillColor': '#8B2222', 'color': '#8B2222', 'marker_color' : 'green'}
style3 = {'fillColor': '#22228B', 'color': '#22228B', 'marker_color' : '#22228B'}
#Create a new Foilum map to show my data
mapOutput = folium.Map(location=oving,tiles="openstreetmap", zoom_start=11)
#Add my polygons
folium.GeoJson(jointPoly, name='Overall', style_function=lambda x:style1).add_to(mapOutput)
folium.GeoJson(ovingPoly, name='Oving', style_function=lambda x:style2).add_to(mapOutput)
folium.GeoJson(Point(oving[1],oving[0]), name='Oving', style_function=lambda x:style2).add_to(mapOutput)
folium.GeoJson(buckinghamPoly, name='Buckingham', style_function=lambda x:style3).add_to(mapOutput)
folium.GeoJson(Point(buckingham[1],buckingham[0]), name='Buckingham', style_function=lambda x:style3).add_to(mapOutput)
#Show the output
mapOutput
and…
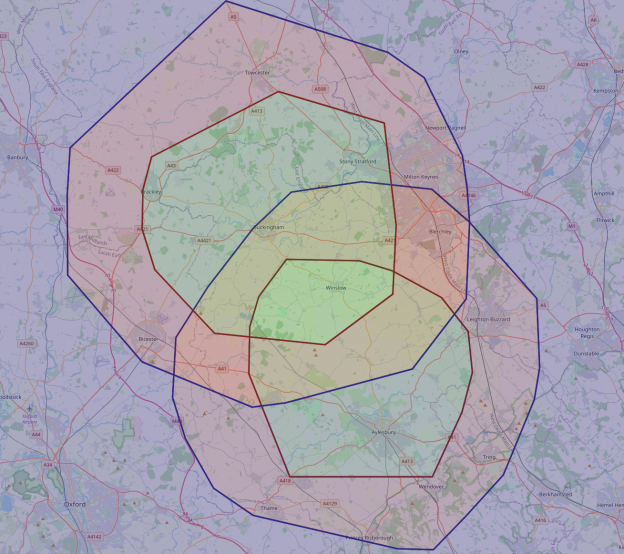
It’s hard to see, but the green polygon is the intersection
Ta-da! we have a working solution.. and much quicker than usual..
But, wait. How is it possible that from the lower location it’s possible to get almost all the way to the upper location, but not vice-versa?
Also, that middle ‘green’ section (which is a bit hard to see) doesn’t entirely cover the intersection.
What went wrong
I think 2 things are broken:
The ‘ego graph’ function isn’t correctly returning the nodes with a travel time
The generated polygons are optimised to enclose regions in a way which could under play the intersection
I think #1 is the result of trying to pull apart another solution, the ego graph is obviously unable to perform the analysis I want to do. I think it’s doing a simpler calculation of all the nodes within 25 connections of the original. The lower point is in a village, and so will need to travel further to reach 25.
#2 is probably more of a finessing problem.
Improving the solution
I need to find a way to identify all the points within a certain drive time of the starting point. Luckily OSMnx has some extra features to help with that.
This should add some extra data to each edge to help compute the travel time between each
#Get the shortest path
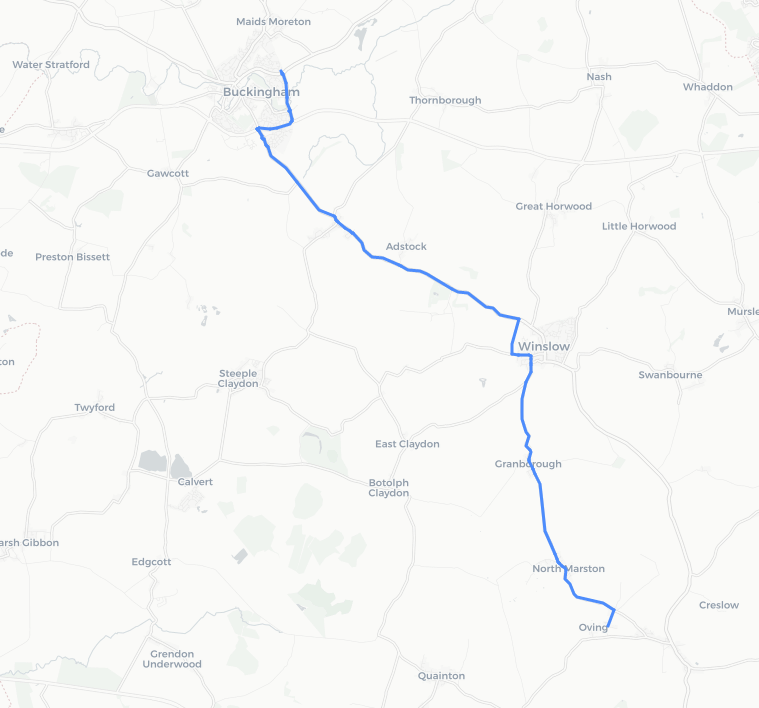
shortest_path = ox.shortest_path(Graw, oving_center_node, buckingham_centre_node, weight='length')
#Plot it on a map
ox.plot_route_folium(Graw, shortest_path)
looks ok, but that route definitely takes in a bridleway.. one for another time!
Weighting it by travel time returns 1040. If that’s in seconds, the trip is about 17 minutes.
I think the journey actually takes more like 25, even if we ignore traffic, I don’t think it’s correctly pricing in the time to accelerate, and things like traffic. But anyway, we have a way forward.
The ‘not very optimal, but will probably work’ solution goes like: Loop through all the nodes in the overall map, check the travel time, keep them (if it’s below the threshold)
ovingPoints = [Point((data['lon'], data['lat'])) for node, data in G.nodes(data=True) if nx.shortest_path_length(Graw, oving_center_node, node, weight='travel_time')<25*60]
So I ran that, and it took ages. There are 39k nodes in that section of the map. There’s going to be a huge amount of recursion going on too, so not very efficient. I need a different approach
Intermission: How *does* google calculate drive time?
While playing around with this I checked the drive time to a few other places and it seems to always be very fast compared to google
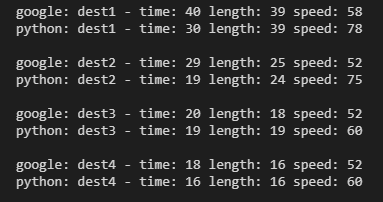
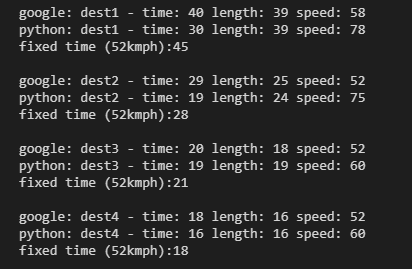
4 random destinations, showing the difference between what google says, and what I’ve got from the code
The distances are thereabouts, the time is the problem. Digging in a bit more, the time calculation is literally adding the time to traverse each edge, assuming you can travel at the maximum speed possible on that bit of road. Not hugely realistic.
The ‘fixed’ time is the time it would take assuming you travel at 52kmph the whole way
I’m not really here to replicate google, at very least I’d just hook into the API, but that’s for another day. For now, I’ll just recalculate my speed for any journey which has an average above 52. This will reduce the likelihood of very distant nodes making it into the allowed zone, which is what I’m wanting anyway.
Back to the problem
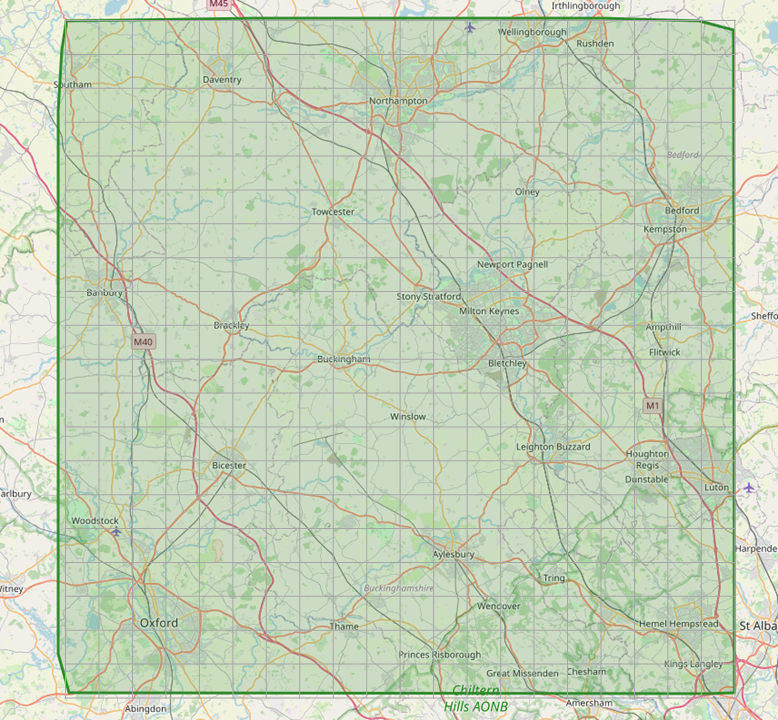
My latest issue is that I can’t check every node in the graph in a reasonable amount of time. So the next idea is to reduce the scope of the checking. I don’t need to check every node, but I want to make sure I cover a reasonable area
The map area in green, with a hypothetical grid over the top
If I imagine a grid over the whole map area, I can loop through regular points on that grid, get a node near the point, and then check the distance from my starting points to that node
Then define 400 boxes and calculate the Lat/Lon points for each
steps=20
grid=[]
for i in range(steps+1):
lat=south+(i*round(north-south,2)/steps)
for j in range(steps+1):
lon=west+(j*round(east-west,2)/steps)
node=ox.nearest_nodes(Graw, lon, lat)
grid.append(node)
Now, loop through each point, find the nearest node, and calculate the time to get to it
ovingPoints=[]
for node in grid:
try: #This is to capture the cases where the selected node has no path back to the origin.. I'm not bothered about these
shortest_path = nx.shortest_path(Graw, oving_center_node, node, weight='travel_time')
length=int(sum(ox.utils_graph.get_route_edge_attributes(Graw, shortest_path, 'length')))/1000 #in KM
time=int(sum(ox.utils_graph.get_route_edge_attributes(Graw, shortest_path, 'travel_time')))/60 #in mins
speed = (length)/(time/60) #speed in kmph
if speed > 52: #If the hypothetical speed is ever greater than 52kmph, reduce it to that number
time = (length/52)*60
newPoint=Point((Graw.nodes[node]['x'],Graw.nodes[node]['y']))
ovingPoints.append((newPoint, time, length))
except:
pass
Finally build some polygons which encompass reasonable travel times, less than 20 mins, 20-30 and 30+
ovingPointsLow = [point for point, time, length in ovingPoints if time < 20]
ovingPolyLow = gpd.GeoSeries(ovingPointsLow).unary_union.convex_hull
ovingPointsMid = [point for point, time, length in ovingPoints if (time >= 20 and time <30)]
ovingPolyMid = gpd.GeoSeries(ovingPointsMid).unary_union.convex_hull
ovingPointsHi = [point for point, time, length in ovingPoints if time >=30]
ovingPolyHi = gpd.GeoSeries(ovingPointsHi).unary_union.convex_hull
ovingPolyHi=ovingPolyHi-ovingPolyMid
ovingPolyMid=ovingPolyMid-ovingPolyLow
And plot the result on a map:
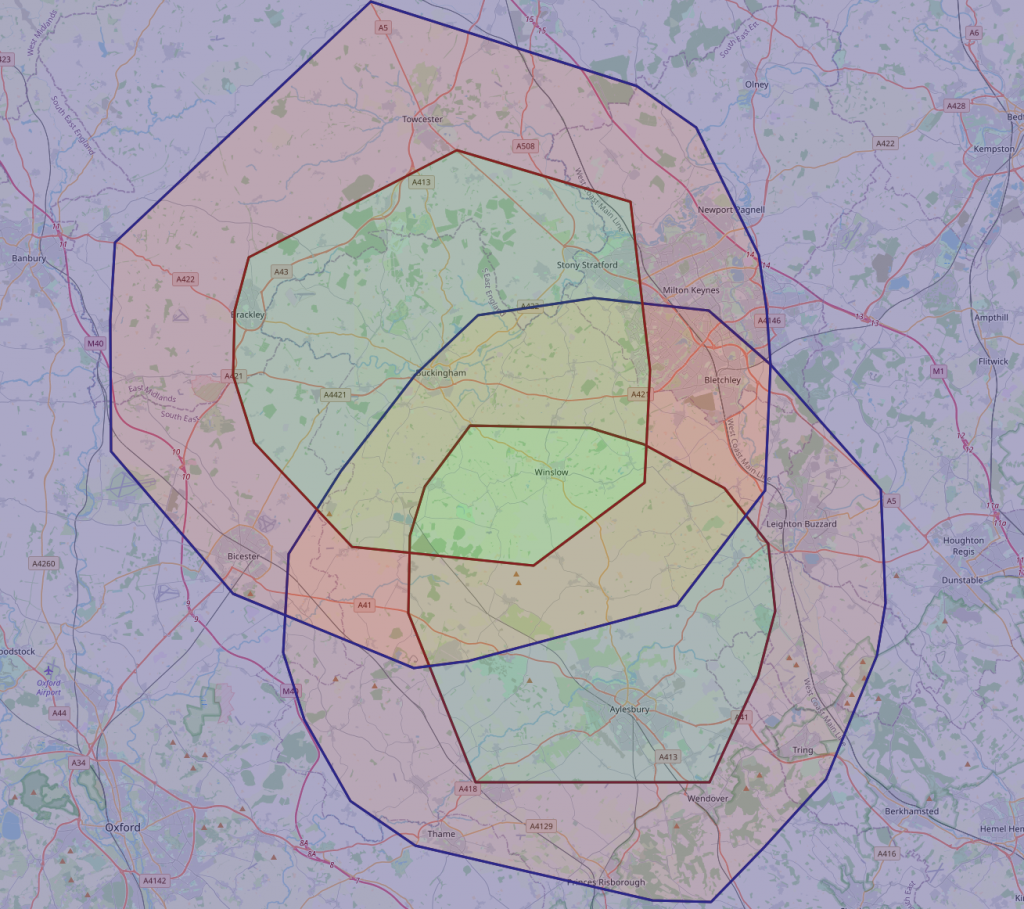
That’s better!
I’m happier with both the extent of the regions (I think that’s a reasonable distance to travel in the time – ignoring rush-hour around Aylesbury)
The regions are also much more circular, and critically, overlap.
Now, a bit more polygon maths and we can calculate the definitive areas of interest
#Create a new Foilum map to show my data
mapOutput = folium.Map(location=oving,tiles="openstreetmap", zoom_start=13)
#Add my polygons
folium.GeoJson(jointPolyLow, name='Low', style_function=lambda x:style1).add_to(mapOutput)
folium.GeoJson(jointPolyLowMid, name='Low', style_function=lambda x:style2).add_to(mapOutput)
#Show the output
mapOutput
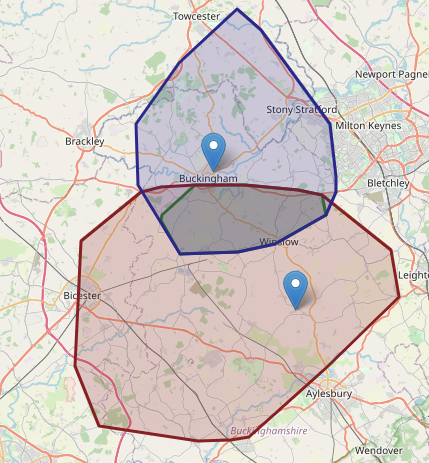
Green is within 20 mins of both, red is 20-30 mins from both
While mulling my options for the next steps on this project, I got some feedback
i think the backgrounds will be your biggest issue…that followed by the healthbars / items equipped…trying to normalise for that will probably help a lot ?
Tom Cronin – via Linkedin
Which completely changed my view on the problem.
Firstly, I’d thought the background were *helpful* – the high contrast with the characters, and then the different backgrounds that players use to provide variety. A problem I’d not considered is how much extra complexity they add into the image, and how much more training might be needed to overcome that.
Secondly, I’d been thinking my task was to collect and annotate as many images as possible.
I’ve been doing it wrong.
The (new) approach
I can easily ‘cut’ the characters out from their backgrounds
Mad as it sounds, I did this in Powerpoint. The ‘background eraser’ tool is the quickest and most accurate I’ve found.
But then the problem is that I don’t want the computer thinking a solid white rectangle is anything meaningful to the character. So what if I take the cut out, and make some new backgrounds to put it on. Then I’m killing two birds with one stone:
I can create any background I like; colours, shapes, pigeons.. and:
I can create LOTs of them
So rather than screenshotting and annotating, my new approach is:
Cut out a lot of character images (this is tedious, but once it’s done, it’s done forever.. or until the next patch)
Create some random backgrounds
Stick the characters over the new backgrounds
Auto-generate the boundaries I had to draw manually last time
Step 0
There’s always a step 0.
Up to this point, I’ve been hacking about, every step is manual, most of them are ‘found’ by clicking up and down through the terminal window.
I’ve now written a single script which automates:
Clear output folders
Create images (and the annotation file)
Create test/train split
Create TFRecord files
(at some point I’ll automate the run too, but this at least gives me a start)
Step 1 – Cut out a lot of images
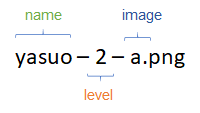
This isn’t very interesting, but I noticed through the process that the characters move about a bit. Just small animation loops for most, but some even flip sides. On that basis, I’ve used a naming convention for the files which allows me to have multiple copies
Each character has 3 levels, which are gained as you get more of them (3 of the same magically transforms into level 2, and 3 level 2s become a level 3). Power increases quite significantly with level.
Here are Yasuo A and B – same colours, but different pose
I keep the first two sections as the class I’m trying to predict, but ignore the suffix.
Step 2 – Create some random backgrounds
Thinking about the backgrounds, I initially went with 2 options – a blurry ‘noise’ of colour, and a single flat colour. The overall intent is that the computer loses the overall background as it learns, and just focuses on the character.
some pixely noise, I’ll assume you can imagine a flat colour
I noticed in early testing that computer was labelling some odd things like parts of my desktop background, while failing on actual screenshots from the game. I decided to add in a handful of random backgrounds from the game (with any characters removed) to give some realism to the sample
one of 8 random backgrounds
Step 3 – Stick the characters over the new backgrounds
I then load a random character image (so random character, level and pose) from my input folder, and add it to the image. I’ve also added a chance for the image to be resized up or down a little before it’s added – this is to cover the slight perspective the game adds, where characters in the background are smaller.
I repeat the loop 20 times for each image, and save it down with the xml
Some of them are in unlikely places, but that should matter less than having accurate backgrounds in thereAVERT YOUR EYES.. this looks horrible, but should help the computer realise the background isn’t important
Step 4 – Auto-generate the boundaries I had to draw manually last time
I was very pleased when this worked.
The most tedious task of the original attempt is now gloriously automated. Each character image reports it’s location and size, and is added in to the correct xml format.
I can now create hundreds, or thousands of files to use as inputs!
So, what does this do to the graph?!
(I should note, with this change I’ve also tweaked some parameter files. I’m not entirely sure of the sensitivity, but each run now uses multiple images. This might only have the effect of doubling the time per step, and halving the number of steps needed. Idk)
Well, a few things look different:
My loss (which I’m assuming is the equivalent of 1/accuracy) behaves much more at the start, and quickly follows a steady curve down.
The time/step is *horrendous* for the first 1k steps. The run above was over 6 hours.
tl;dr – did it work?!
Assuming no prior knowledge, I can tall you that every guess is correct.
Just a bit.
This isn’t just better, it’s remarkable. Every character is guessed, and the strength of the prediction is almost 100% each time. It’s spotted the difference between the Level 1 & 2 Vi, and even handled the inclusion of an ‘item’ (the blue sparkly thing below her green health-bar)
Appendix
The early run (pre the inclusion of backgrounds) did better than before, but still lacked the high detection numbers of the most recent model
This is based on the same character images, but the model also has ‘real’ backgrounds to sample too
It’s especially confused when the background gets more complex, of there’s overlap between the characters.
I’ve also started looking at running this on screen capture, rather than just flat images. I think the hackiness of the code is probably hampering performance, but I’m also going to look at whether some other models might be more performant – e.g. those designed for mobile.
Even with the low frame-rate, I’m delighted with this!
Teamfight Tactics (TFT) is an auto-battler game in the League of Legends universe. Success depends on luck, strategy, and keeping an eye on what your opponents are doing. I wonder if I can use the supreme power of TensorFlow to help me do the last bit?
I won’t bother explaining the concept, for now, just that it’s useful to know what all the things on the screen above are
The problem
Given a screenful of information, can I use object detection & classification to give me an automated overview?
What I’ve learned about machine learning
I usually write these posts as I’m going, so the experience is captured and the narrative flows (hopefully) nicely. But with this bit of ‘fun’ I’ve learned two hard facts
Python, and it’s ecosystem of hacked together packages, is an unforgiving nightmare. The process goes like this: a) install package, b) run snippet of code, c) try to debug code, d) find nothing on google, keep trying, e) eventually find reference to bug reported in package version x f) install different version [return to b]. It’s quite common to find that things stopped being supported, or that ‘no-one uses anything after 1.2.1, because it’s too buggy’. It’s also quite common to only make progress via gossip and rumour.
The whole open source ML world is still very close to research. It’s no wonder Google is pushing pre-packaged solutions via GCP, getting something to work on your own PC is hard work, and the steps involved are necessarily complicated (this *is* brain surgery.. kinda)
But I’ve also found that I, a mere mortal, can get a basic object detection model working on my home PC!
The Approach
This is very much a v0.1 – I want to eventually do some fancy things, but first I want to get something basic to work, end to end.
The very basic steps in image detection & classification. The black box is doing most of the interesting stuff
Here are the steps:
My problem – I have an image containing some (different) characters which I want to train the computer to be able to recognise in future images
I need to get a lot of different images, and annotate them with the characters
I feed those images and the annotations into a magic box
The magic box can then (try to) recognise those same characters in new images
One of the first things I’ve realised is that this is actually two different problems. First, identify a thing, then try to recognise the thing
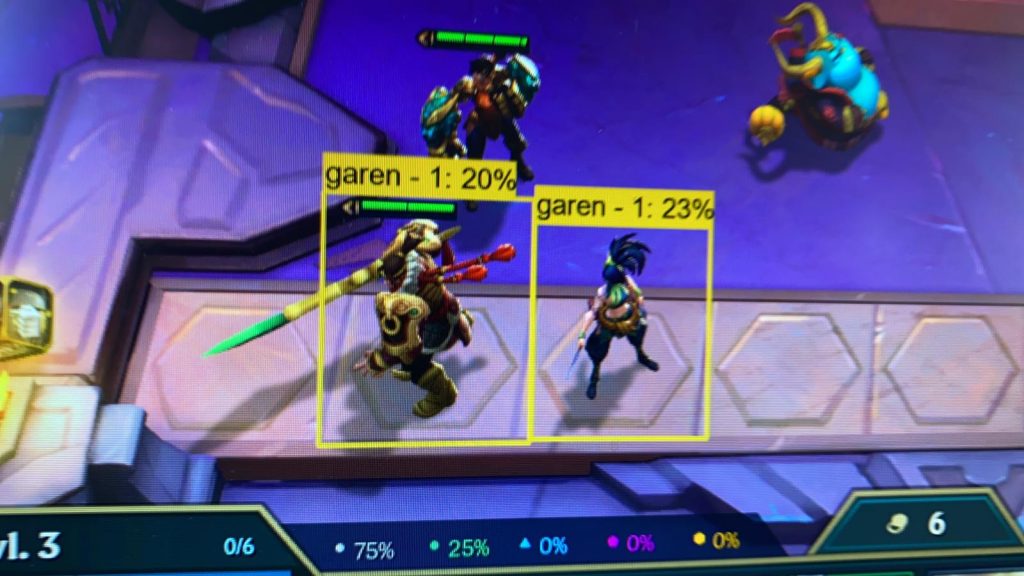
One of these is Garen, the other is Akali. The confidence in the guess is misplaced.
In this early run, which I did mainly to test the pipework, the algorithm detects that the 2 characters in the foreground are present, but incorrectly labels one of them. In it’s defence, it’s not confident in EITHER.
So, to be clear, it’s not enough that I can teach it to recognise ‘character-like’ things, it also has to be able to tell them apart.
Step 1: Getting Tensorflow installed
I’ve had my python whinge, so this is all business. I tried 3 approaches:
Install a docker image
Run on a (free) google colab cloud machine
Install it locally
In the end I went with 3. I don’t really understand docker enough to work out if it’s broken, or I’m not doing it right. And I like the idea of running it locally so I understand more about the moving parts.
I followed several deeply flawed guides, before finding this one (Installation — TensorFlow 2 Object Detection API tutorial documentation) which was only a bit broken towards the end. What I liked about this was how clear each step was, and upto a certain stage, everything just worked.
Step 2: Getting some training data
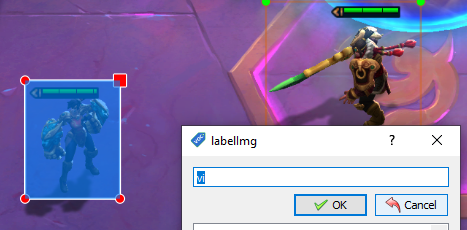
I need to gather enough images to feed into the model to train it, which I’m doing by taking screenshots in game, and annotating them with a tool called labelImg
This is the less glamourous bit of machine learning, drawing boxes around everything of interest, and labelling them
I’m not sure how many images I need, but I’m going to assume it’s a lot. There are 59 characters in the game at the moment, and each of those has 3 different ‘levels’. There are also other things I’d like to spot too, but for now, I’ll stick with the characters.
I’ve got about 90 images, taken from a number of different games. The characters can move around, and there are different backgrounds depending on the player, so there should be a reasonable amount of information available. There can also be the same character multiple times on each screenshot.
I started out labelling the characters as name – level (e.g. garen – 2), which is ultimately where I want to be, but increasing the number of things I want to spot, while keeping the training data fixed means some characters have few (or no) observations.
Step 3: Running the model
I’m not going to describe the process in too much detail, I’ve heavily borrowed from the guide linked earlier, the rough outline of steps is as follows:
Partition the data into train & test (I’ve chosen to put 25% of my images aside for testing)
Build some important files for the process – one is just a list of all the things I want to classify, the other (I think) contains data about the boxes I’ve drawn around the images.
Train the model – this seems to take AGES, even when run on the GPU.. more about this later
Export the model
Import the model and run it against some images
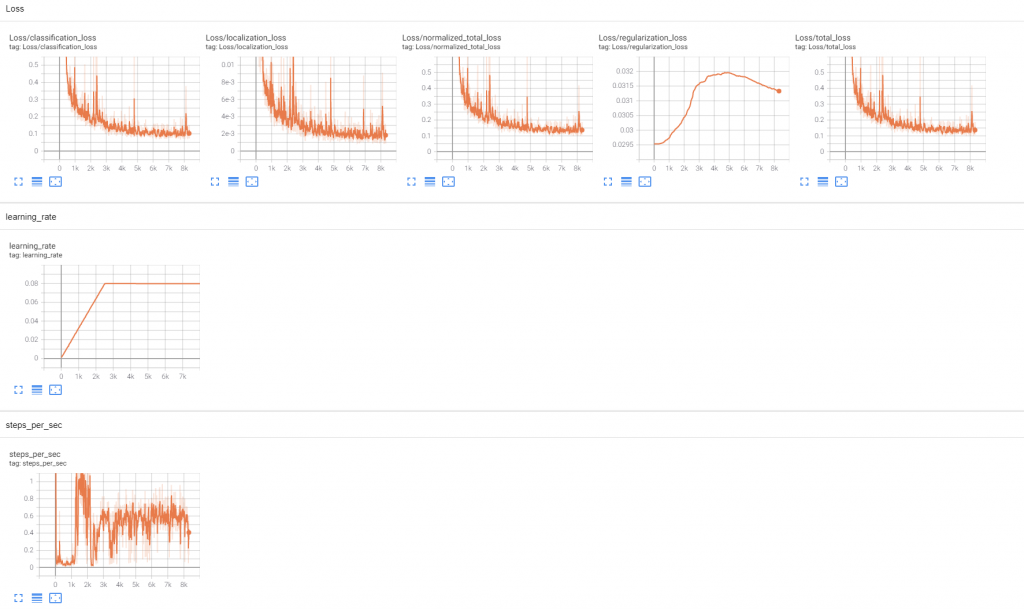
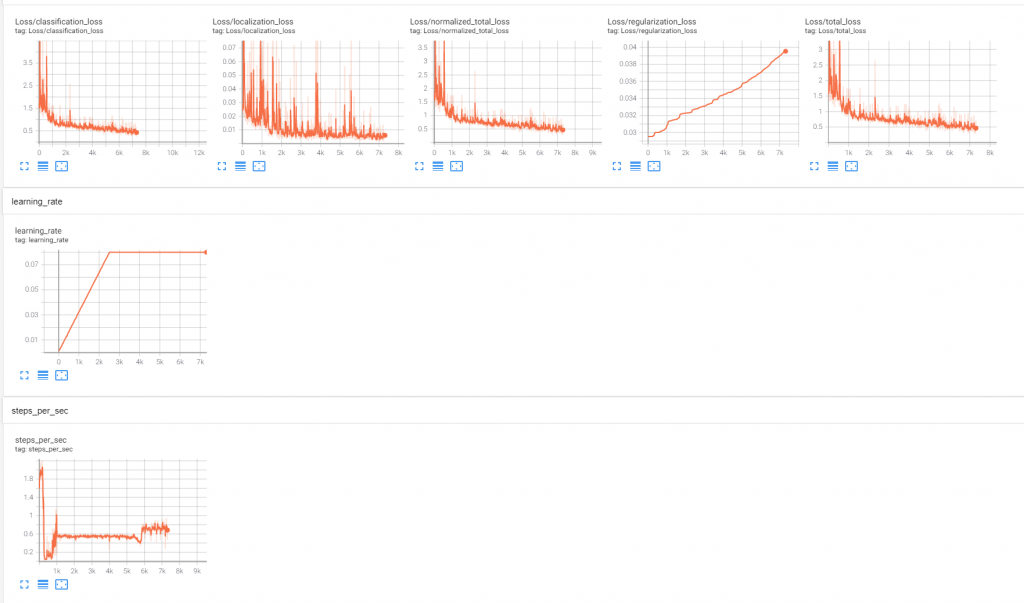
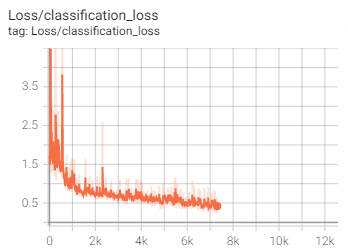
During the training, I can monitor progress via ‘Tensorboard’, which looks a bit like this:
I’m still figuring out what the significance of each of these measures is, but generally I think I want loss to decrease, and certainly to be well below 1.
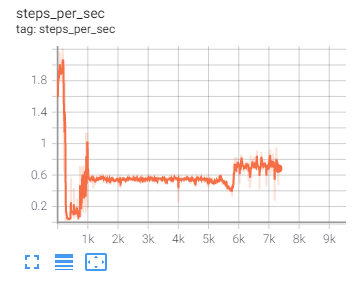
An interesting thing I noticed was that the processing speed seems to vary a lot during run, and particularly drops off a cliff between steps 200 and 300
I’m not sure why this is happening, but it’s happened on a couple of runs, and when the speed increases again at around step 600, the loss becomes much less noisy
I should get a more zoomed in chart to illustrate, but you can see that the huge spikes disappear about half-way between 0 and 1k steps
There seems to be a gradual improvement across 1k+ steps, but I’m not sure if I should be running this for 5k or 50k. I also suspect that my very small number of training images means that the improvement will turn into overfitting quite quickly.
Step 4a: The first attempt
I was so surprised the first attempt even worked, that I didn’t bother to save any screenshots of the progress, only the one image I gleefully sent on whatsapp
At this stage, I realised that getting this to work well would be more complicated, so I reduced the complexity of the problem by ignoring the character’s level
Vi level 1, left, Vi level 2, right
The characters do change appearance as they level up, but they’re similar enough that I think it’s better to build the model on fewer, more general cases.
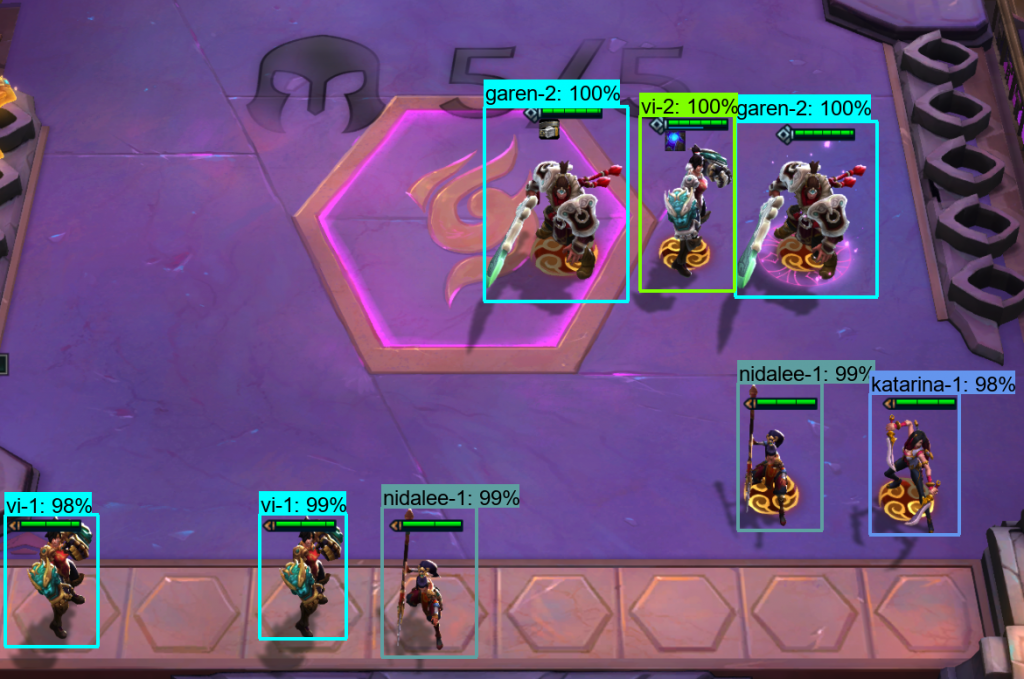
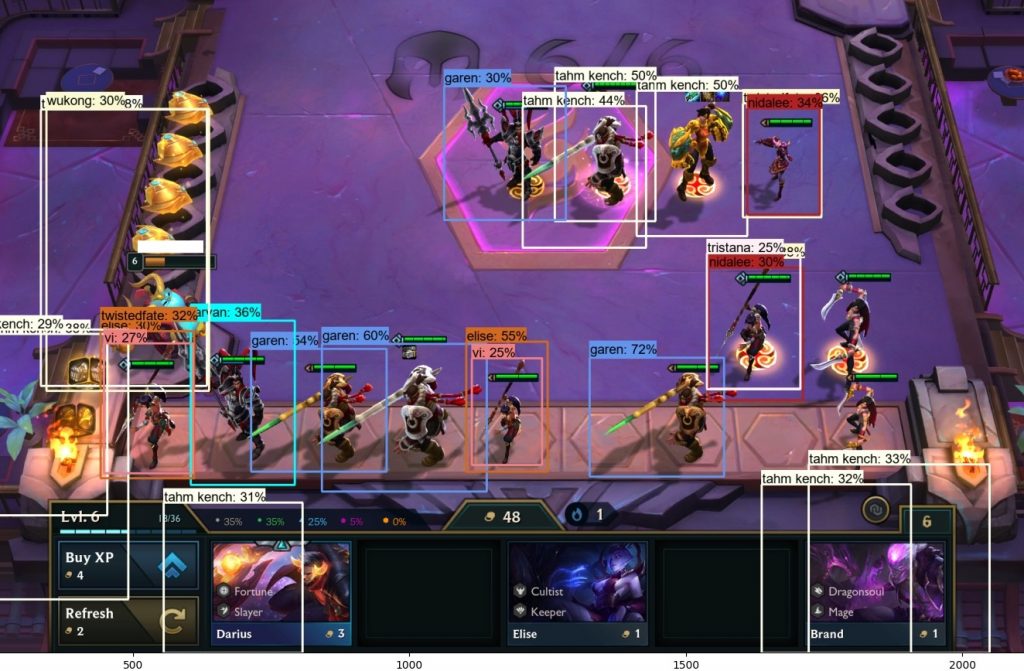
Step 4b: The outcome
(this is correct)
Success! A box, drawn correctly, and a name guessed which is correct!
hmm.. maybe a bit less correct
Ok, so that first one might be a bit too good to be true, but I’m really happy with the results overall. Most of the characters are predicted correctly, and I can see where it might be getting thrown by some of the graphical similarities
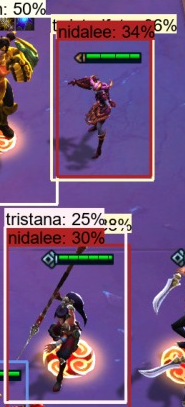
Here, for example, the bottom character is correctly labeled as Nidalee, but the one above (Shyvana) has a very similar pose, so I can imagine how the mistake was made
And here, the golden objects on the side of the screen could be mistaken for Wukong.. if you squint.. a lot
Next steps
I’m really pleased with the results from just a few hours of tinkering, so I’m going to keep going and see if I can improve the model, next steps:
More training data
Try modifying the existing images (e.g. removing colour) to speed up processing
Look at some different model types
Try to get this working in real-time
Most of the imagery on this page is of characters who belong to Riot, who make awesome games