A long time ago, I was sat in a corner of an office, and was involved in a conversation with a guy who made a small passive income from a website which contained some relatively trivial information, but for reasons I won’t describe, was highly searchable.
When LLMs came along, I started to think about how I could try and do something similar. I’m not sure when the idea for a website about people’s names came to me, but it seemed to fit the brief:
- Highly searched (‘what does my baby’s name mean?’, ‘what are names like X?’)
- Low impact of wrongness (who’s to say what Alex really means?)
- Potential to generate both specific content about names, then click-baity articles about those names
All toegther, this seemed like a possible winner: Get the site up and running, pop some content in there, adsense, ???, profit!
Here’s the result, if you want to skip to the good bit: https://namesphere.co.uk
The architecture
I’d used HTML and PHP a lot as a ‘kid’, and even scored a job building a website for a schoolfriend’s family business. More recently I’d got something working in Angular, so that seemed a sensible start
I wanted to avoid any cost for this project, other than maybe a domain and some setup, so I came across Firebase, and it seemed to have decent documentation for Angular deployments. The content of the site would sit in Firestore, and be called dynamically into my Angular app.
This ended up biting me pretty severly, as although everything worked ok, the dynamic site rendering was only crawlable by Google.. more on that later.
The content
I’d played with some offline LLMs when they first hit the headlines, and the wrappers have only improved since.
koboldcpp – let me run any models I liked, with CUDA optimisations, in windows. Crucially it also came with a local API interface. I just wanted quick-start, so this was perfect
TheBloke – I can’t remember how I found this person’s work, probably a reddit post/tutorial, but I really liked the way they summarised the model quantisations they’d made. In the end, I used a mix of capybarahermes 2.5 mistral models for the gen.
I wanted to do two things:
Defintions – a page for each of the names, with a set amount of content, e.g. a defintion, some alternative names, then some other fillere
Articles – some text which pupported to be magazine content written by different authors for a website about names – this would be the dynamic content which might help funnel traffic.
Definitions
I got a list of names from the ONS, and then did an unnecessary amount of processing on it. First I wanted to remove male/female duplication, then I wanted to sort by a sensible measure of popularity – initially I might only work on the most popular names.
One of the biggest issues was getting the LLM response to neatly fit a website template. I iterated over a lot of different prompts, eventually settling on:
<|im_start|>system
You are a helpful staff writer and researcher for a website which specialises in peoples names, their origins and meanings. you reply truthfully. you always reply with html formatting<|im_end|>
<|im_start|>user
I'd like to know more about the name {name}. please complete the following sections, please wrap each section heading in an <h2> tag, and the remaining text in a <p> tag. The list should be in <ul> with <li> elements. do not use <strong> tags. you may use </ br> line breaks if needed.
origin
meaning
current usage
aspirational summary
5 common nicknames
<|im_end|>
<|im_start|>assistantInitially I’d gone for a more robust approach of each section separately, but with around 30k names, this was just taking too long. It was quicker to have each name return all the data.. but.. at the cost of less reliability in the output
In the end I applied a section ‘reviewer’ stage which checked for the basics, like number of html tags. Any names which failed were requeued for generation, and it usually worked second time around.
The Data
The records were stored as the HTML which would be injected into my angular template. This massively increased the potential for any janky formatting from the LLM to get into the site, but typically the output was very good.
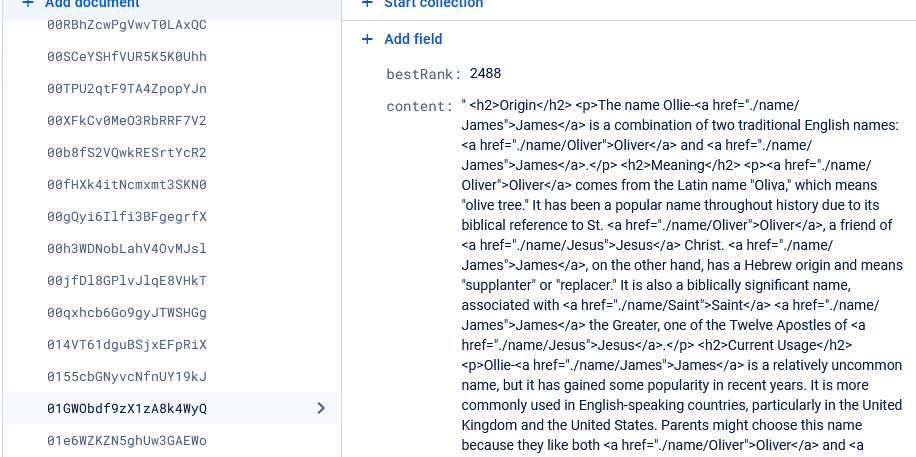
And after a few days of batch running/cleansing, I had a lot of defintions
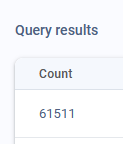
I haven’t checked even a fraction of the total, but every one i’ve seen looks like a reasonable output. Certainly enough to get some clicks!
Articles
This was a bit more fun, and I went overboard.
First I used ChatGPT to create a set of author personas – one of my key findings here is how much more reliable and fast ChatGPT is than anything I worked with offline.
Then I had a separate ‘Editor’ who prompted each writer with some ideas of what was wanted. This was utterly overkill, and I spent a lot of time just making this ‘office politics’ work properly.
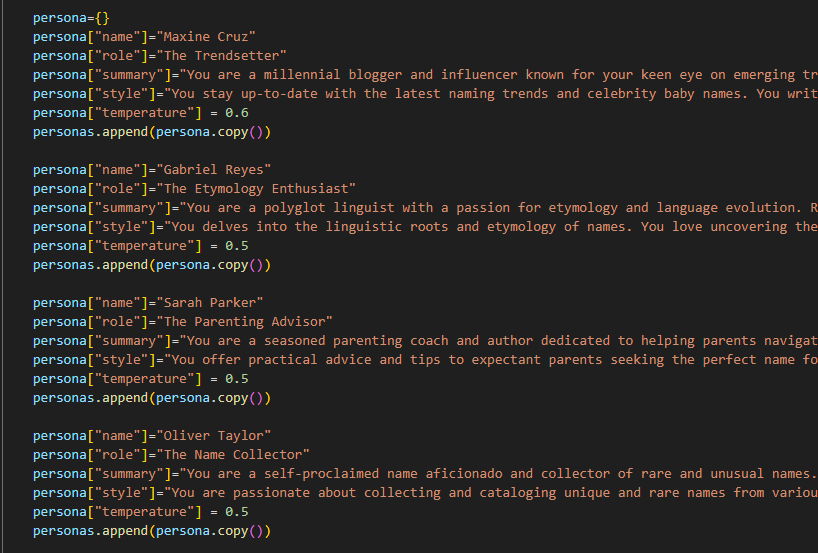
The articles were then served up via a flask front end, so I could make tweaks, and eventually upload them to the site.

I saved a lot of the data from the early steps so I could re-run and tweak as needed
Namesphere
No idea why I called it that.
Now I’ll be the first to admit that I shouldn’t be allowed anywhere near a website editor, but, here it is:
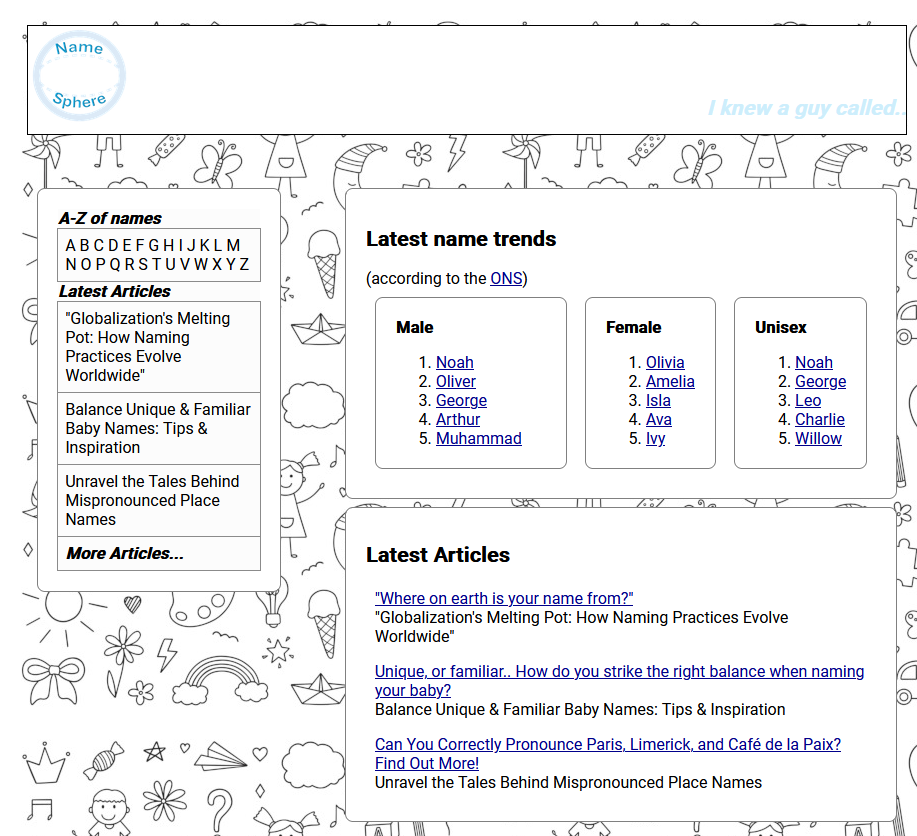
My articles were attributed, and contained links to the appropriate detail:
And then the name defintions sat seperately:
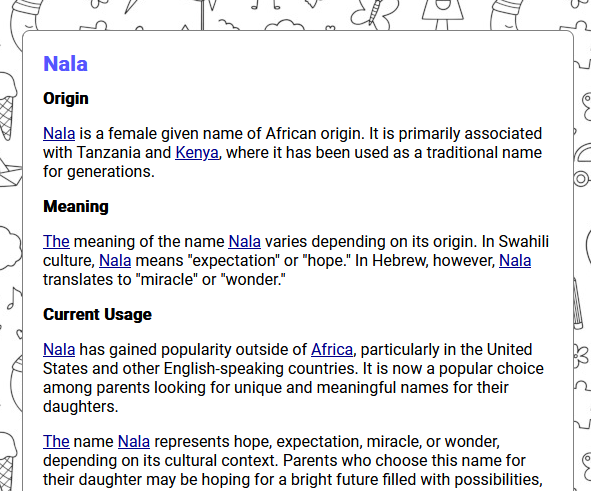
The result
It actually worked.
I’d burned probably 24-36 hours of PC time, with my trusty nvidia 3070 doing a lot of the work, but I had a massive amount of content.
The output
One of the things which suprised me the most was how I never found a dodgy bit of information in the output. Somehow, coded in each of my 4-8gb models was a staggaring amount of detail about the naming practices of different cultures. Especially if you aren’t worried about being sued for getting it wrong
The formatting remained an issue. Particularly for the articles, some of my writers would go off the deep end, and produce something which couldn’t be easily returned to the formatting I wanted.. but.. I could re-run the whole thing in a few minutes, and it usually came good in the end.
My millions
I’m writing this from the Maldives, where my passive income has…
No.
Sadly not.
With everything up and running, I’ll admit I got very excited. I started getting into SEO articles, worrying about the way Angular’s client rendering handled meta tags, and was even arrogant enough to apply to adsense.
And with, kind of, good reason:
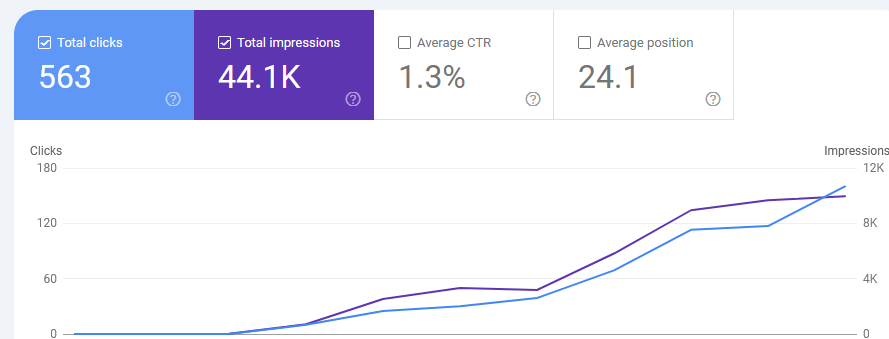
That’s my first 10 days since launch. I felt giddy.
Then it all went wrong. This is the full picture, to roughly today.
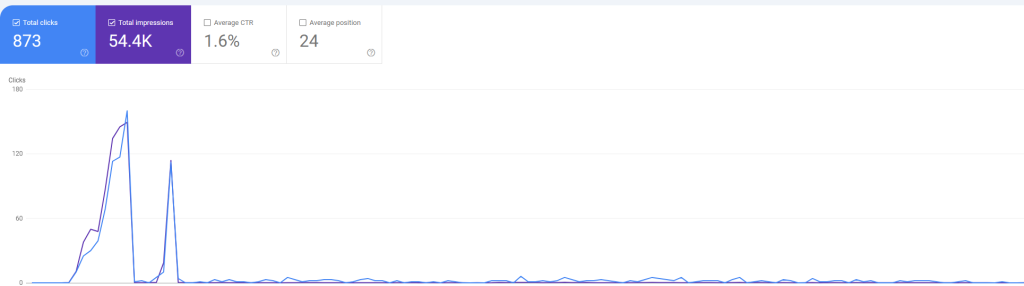
I’ll never know for sure if I got lucky at the start, or unlucky at the end (reddit tells endless stories about google’s algorithm changes). Honestly it’s probably for the best that my clearly AI generated content isn’t making it to the first page of the worlds biggest search engine.
My decision to use Angular and dynamic data also torpedoed my ability to list with other engines.
What did I learn?
- LLMs/GenAI are really cool, and for a certain set of circumstances, you can get amazing things from them
- Angular is a PITA. No tool should be releasing major version increments that often. It risks looking like Python’s package black-hole.
- There’s no such thing as a free lunch – Maybe my next idea will be a winner, but for now, I’m at least pleased my bill has been essentially £0
Perhaps when I have a few minutes I’ll create a static version of the site, and have a go at automating some social media engagement drivers. Watch this space!
Do you consider the possibility that AI-generated websites are filtered from Google Search?
It’s definitely not _filtered_ as I still get search hits.. but I think you’re right that they’ve tried hard to detect AI content and downrank it.
https://www.bbc.com/future/article/20240524-how-googles-new-algorithm-will-shape-your-internet
How good is an AI at detecting AI? I wonder how many legit sites have been squashed by this?