There’s a thing I see all the time, working in and around Data & Analytics, which I think is making our lives more difficult than it needs to be. I’ve started (humbly) referring to it as Dunning-Kruger-Chatwin: an extension of the idea that people tend to over estimate their abilities in areas they know little about:
When faced with a problem, there’s a tendency of people within a specialisation to overthink the importance of their own expertise..
..and underappreciate the need for related disciplines to be involved
Me – 2023(ish)
What does that mean?
Specialisation of D/A roles
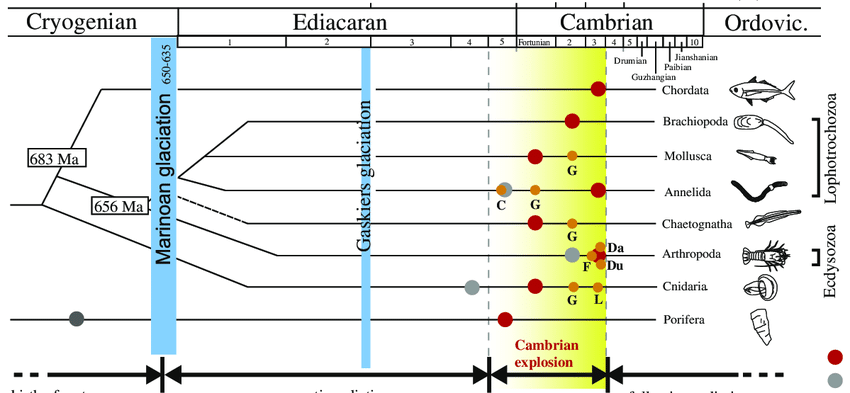
A very long time ago everyone who worked with data was either a DBA or an Analyst*. Sometime in the early 2000s a kind of Cambrian Explosion started, fuelled by an increasing focus on the value of Data, big leaps in computational power, and the availability of new and more powerful tools.
These factors have lead to lots of new specialised roles, some of which (e.g. Data Engineer, Data Scientist) are viewable as direct descendants, others (e.g. Experimentation, Behavioural Economics) have grown as funky cross-overs* with other fields, or ways to solve problems.
Like the specialisation in early industry, this is generally a great thing. It’s supported big leaps in the benefits which can be created, and created a positive reinforcement cycle which includes things like the Chief Data Office concept, and myriad degrees and qualifications.
Specialise or die..?
Let’s consider two of the ways a Data Scientist is born – I’d argue there are similar stories for all the D/A specialisations

There’s a huge amount of social and corporate pressure for generalists to specialise. Data Science is rife with this. A ‘standard’ Analyst is bombarded with stories of the cool things DSs work on, the allure of Python, and the promise of more pay and seniority.
I’ve had dozens of conversations with analysts who wanted in to the DS world like they were trying to get tickets to see a band they’d only heard others talking about. To torture the metaphor: they can get into the gig before they really know if they like the music..
At the same time Universities have responded to the market pressure and created degrees, masters and doctoral qualifications which turn out highly technically qualified experts, but at the cost of a lack of practical business experience, which the Analyst->DS progression route avoids.
I’ve plenty of conversations with incredibly smart people who just want to make models, use new and more complex techniques. write articles and paper – and don’t care about the realities of delivering stuff in a business (deadlines, benefits, politics etc)*.

Neither of these routes is better than the other. I point them out to show that whichever type of DS you have in front of you, the inherent pressure on them is to get better at being a DS.
Solving problems as a specialist
Then a call comes in from the business – ‘We need a <data thing> to solve a <business problem>‘.
That request often has nowhere to go but a senior person in a team of specialists*. Hopefully some logic goes into who gets asked, based on the problem.. but not always. That senior person will use the scoping/planning/etc processes at their disposal, and soon a new project will be created.
And that project will be at risk. Why? Because most solutions don’t sit cleanly in a silo.
Even if the majority, even the overwhelming majority of a problem is actually a Data Science problem, there is always a need to bring in some data, or connect the outcome to a system, or visualise the result.
Specialists struggle with that, because it goes outside of their expertise, and it’s not the thing they’re incentivised to get better at. It’s down to the individual whether they reject/ignore the task, or try to helpfully reroute it, but often by that point it’s too late.
Dunning-Kruger-Chatwin
Here’s a comically simplified soultion map drawn from the point of view of a rigidly specialist Data Scientist*:

And the same thing from a rigidly specialist Data Engineer*:

Each puts a box (or two) in for the other, but look at the gaps:
You end up with a model based on rubbish data, which ends up taking years of rework to get into production.
OR (maybe)
You have a set of beautiful pipelines which after months of delay, it turns out the solution wasn’t modelleable anyway.
Look at the details too – The DS could be deep into auto-retraining before they think about where the data will be going.. and the DE could be worrying about the orechestration framework before wondering if the problem could be solved with a look-up*.
This is a trivial example. I borrow the bones of it from actual problems I’ve walked into the middle of, and tried to help clear up.
This is Dunning-Kruger-Chatwin. It’s real, it happens all the time in big and small ways, but the ultimate effect is we all look worse in the eyes of our stakeholders.
Why does this happen?
Something got lost on the journey of specialisation. I think it may now be being addressed by the concept of Data Products, but it’s not solved yet.
Let’s revisit the specialisation explosion from the point of view of a D/A team:
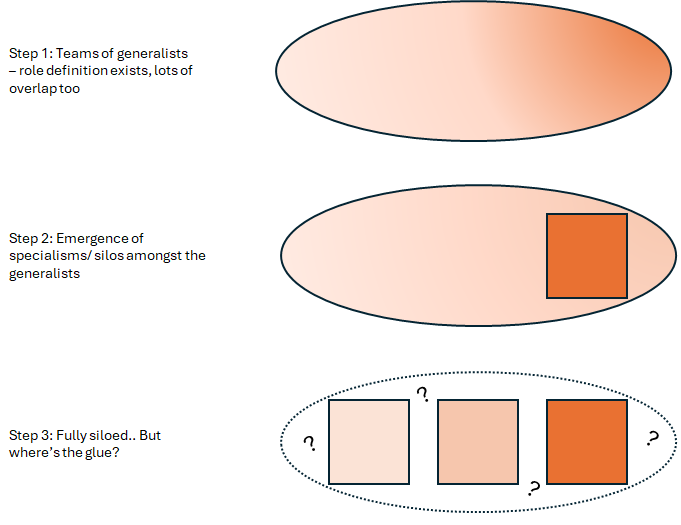
As the maturity of the team increases, there’s a push to specialise some of the roles, and that leads to big benefits. But as the whole team becomes siloed into specialisms, something is missing.
‘The Glue’ was originally the fact a single person could be responsible for the end to end. But the end to end in question was probably pulling some data from a stored SQL query into Excel with a nice VBA button.
But the world is more complicated now. That process could easily involve bespoke pipelines of data, complex summary statistics, and a whizzy UI. It’s not practical for specialist in any team to be able to do the whole thing, and, critically, there’s noone left who isn’t a specialist to take it on*.
How do we avoid this?
I think there are novel solutions out there, be it explicitly organising delivery around a Data Product, or just promoting workflows and processes which assume (rather than ignore) inter-connectivity.
I’d push for two (partial) solutions:
Make space for generalists – We shouldn’t be trying to undo the amazing leaps that have been made in the field. We (the D/A professionals) are richer because of it.
We should be making sure that generalism is respected and nourished as part of the curriculum that all D/A professionals follow. You don’t have to be an expert in every last part of the chain, you just have to be aware.
Be interested and open across silos – Most of these problems are solved by having enough respect for the whole problem to know when you are and aren’t qualified, and talking to other people.. but.. if you do realise you need more technical know-how to get a solution scoped, you need to know where to go to start the conversation, and that you won’t be shunned when you get there.
There’s an ugly side to specialisation which encourages fiefdoms and disrespect. It can stem from controlling leaders, inflexible procedures, or simply a lack of time.
By the way: It’s not just within D/A
I’m particularly interested in solving this problem in my own back yard, but DKC only gets bigger as you zoom out and involve more specialisms from across organisations – Risk and Data is often a spicy one* – again, these things usually start as a lack of understanding, which morphs into frustration, and eventually becomes a blocker.
Notes:
Wherever you see (*) please assume I’m simplifying deliberately, and absurdly, but knowingly 😀